Rasa: how do I hate thee? Let me count the ways
Rasa gets many things right, and only really gets one thing wrong, in my humble opinion. However that one is a real killer for creating professional bots.
Let’s start with the good things. Rasa has excellent documentation. There is a fun tutorial that shows you how to build a bot with a tiger cub. Perfection indeed.
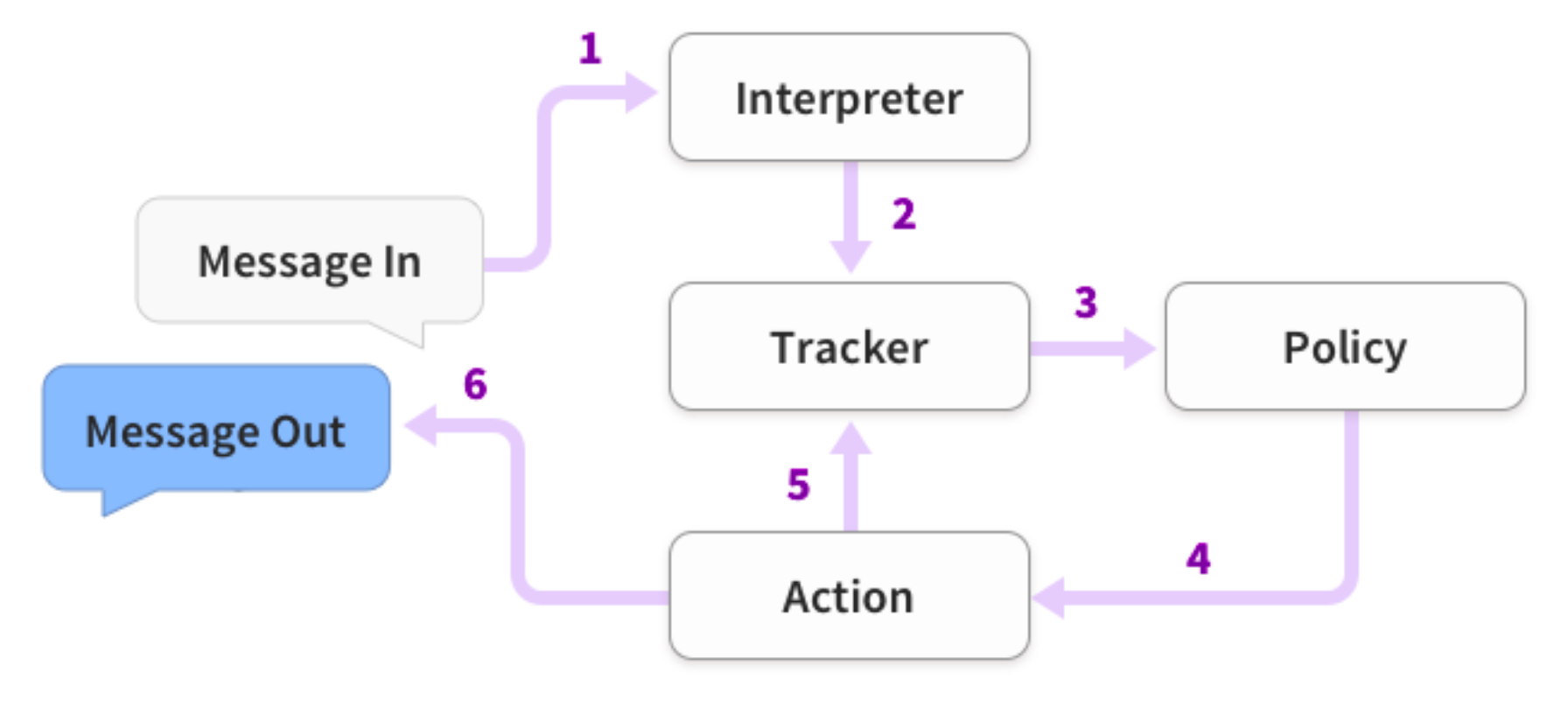
Rasa makes it really easy to create a bot. I’ve categorised it as a “developer tool”, but really, if you’re comfortable on the command line, you could probably use it to make simple bots. All you have to do is edit a few text files. These allow you to train the different components used in Rasa, which plumb together like this (stolen from Rasa’s documentation):
The first file you write defines the “domain”. This specifies (stolen again):
- Intents: things you expect users to say
- Entities: pieces of info you want to extract from messages
- Actions: things your bot can do and say
- Slots: information to keep track of during a conversation (e.g. a users age)
- Templates: template strings for the things your bot can say
This file basically defines the scope within which the bot can learn and act.
Next, we need a file that is used to train the semantic parser, or
“interpreter” as they call it. This contains training expressions for
each intent, for example, “hey”, “hellow” and “hi” are all associated
with the greet intent. I can’t really see how you can escape having
something like this without using some third party tool that has
access to a lot of training data.
Finally, we have a file that defines example “stories”. These are sequences of user and bot actions, that specify ideal actions for the bot to take in each scenario. These stories are used to train a dialogue model (using a deep neural network) which will then be able to predict in any given state, which is the best action to take.
Clever stuff.
Or is it? This is the bit that I have a problem with. When I first saw this, all my data science instincts, honed over the years, screamed, “Noooo, this is wrong!”
How do I hate thee? Let me count the ways.
The biggest problem is that it is using machine learning to do something that doesn’t need machine learning. That is always a big no-no, because machine learning is very rarely 100% accurate. If you can build something that fits all the use cases without machine learning, and without over-complicating your system, then you should use that. The reason is simple: engineering. When a system is engineered, you can find bugs in it and you can fix them. When a system is a deep learning black box, if something is wrong, all you can do is throw more data at it.
That brings me to the second issue: training data. Deep learning generally works well with a lot of data. How much data do I need? I don’t know. The simple example in the tutorial works fine with just a little data. But what if I’m building a complex system? What if I’m building a bot to help people with first aid, say? There are lots of different routes the conversation could follow. Do I need to write out each one? Or is a sample of them enough?
The Rasa designers here have made a trade-off here, and it’s a trade-off that smells bad to me. The trade-off is bot developer thinking time, for quality of the end product. Basically, you don’t need to think about how your bot should behave, just throw a bunch of examples at a deep learning algorithm, and it will all be good. Eventually. Perhaps.
And back to the first aid example. There are contexts where it’s serious if the bot makes a mistake. At least if we’ve specified the logic for the bot, we know we are the ones to blame if the bot gives bad advice. If we’re relying on deep learning then we didn’t have enough training data, or we didn’t use enough epochs to train the model, or perhaps we need to tune the parameters… It’s a bad trade-off indeed.
This is just my personal opinion. But I happen to feel strongly about it. Don’t use Rasa for anything unless you’re happy for your bot to be wrong occasionally. Having said that, it’s still a good framework. And it has baby tigers.